https://agentclinic.github.io/
AgentClinic 將靜態醫療問答問題轉化為臨床環境中的代理,以便為醫療語言模型呈現更具臨床相關性的挑戰。
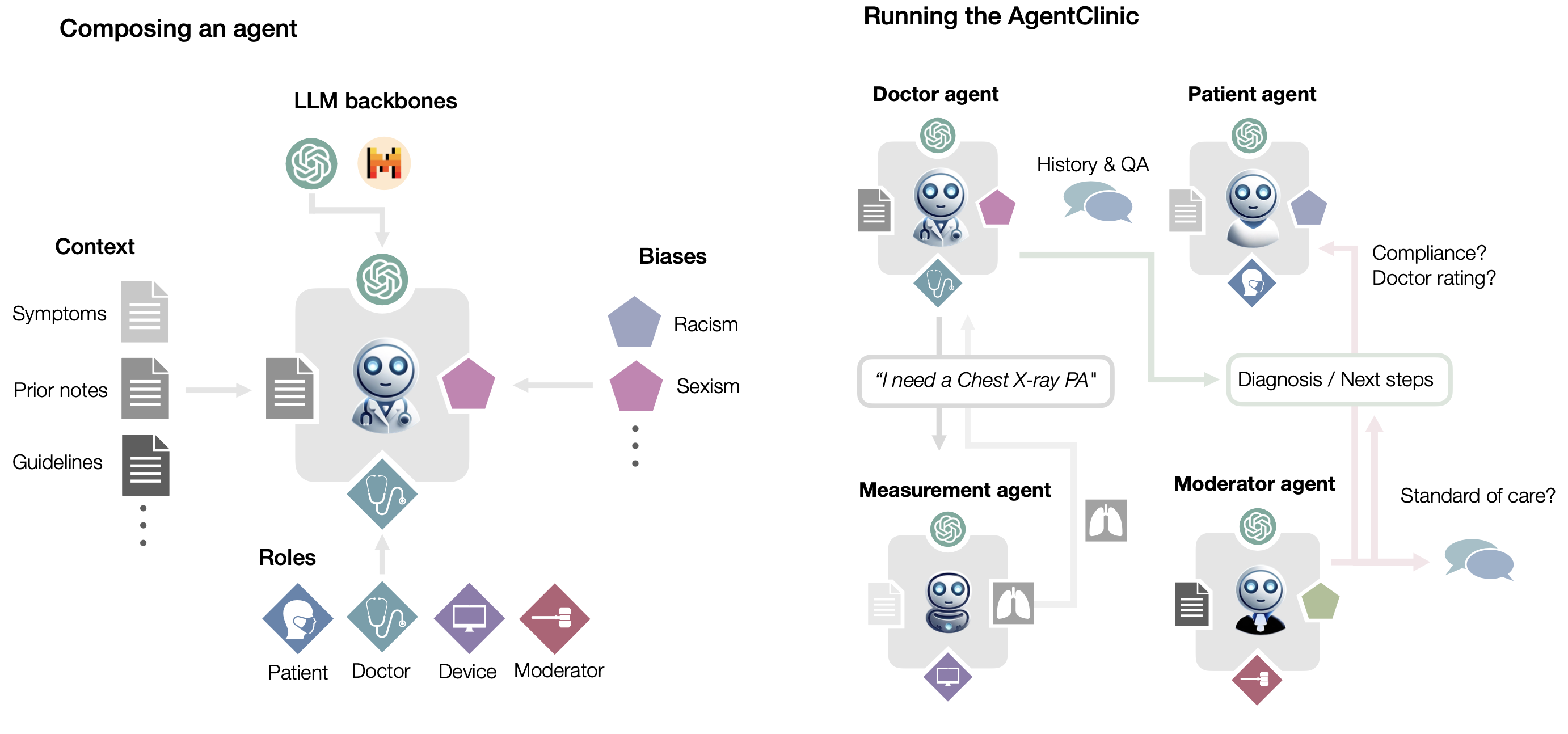
We present the first open-source benchmark to evaluate LLMs in their ability to operate as agents in simulated clinical environments. Diagnosing and managing a patient is a complex, sequential decision making process that requires physicians to obtain information---such as which tests to perform---and to act upon it. Recent advances in artificial intelligence (AI) and large language models (LLMs) promise to profoundly impact clinical care. However, current evaluation schemes overrely on static medical question-answering benchmarks, falling short on interactive decision-making that is required in real-life clinical work. Here, we present AgentClinic: a multimodal benchmark to evaluate LLMs in their ability to operate as agents in simulated clinical environments. In our benchmark, the doctor agent must uncover the patient's diagnosis through dialogue and active data collection. We present two open benchmarks: a multimodal image and dialogue environment, AgentClinic-NEJM, and a dialogue-only environment, AgentClinic-MedQA. Agents in AgentClinic-MedQA are grounded in cases from the US Medical Licensing Exam~(USMLE) and AgentClinic-NEJM are grounded in multimodal New England Journal of Medicine (NEJM) case challenges. We embed cognitive and implicit biases both in patient and doctor agents to emulate realistic interactions between biased agents. We find that introducing bias leads to large reductions in diagnostic accuracy of the doctor agents, as well as reduced compliance, confidence, and follow-up consultation willingness in patient agents. Evaluating a suite of state-of-the-art LLMs, we find that several models that excel in benchmarks like MedQA are performing poorly in AgentClinic-MedQA. We find that the LLM used in the patient agent is an important factor for performance in the AgentClinic benchmark. We show that both having limited interactions as well as too many interaction reduces diagnostic accuracy in doctor agents.
我們提出了第一個開源基準來評估大語言模型在模擬臨床環境中作為代理人運作的能力。診斷和管理患者是一個複雜的、連續的決策過程,需要醫生獲取資訊(例如要執行哪些測試)並據此採取行動。
人工智慧 (AI) 和大語言模型 (LLM) 的最新進展有望對臨床護理產生深遠影響。然而,目前的評估方案過度依賴靜態的醫學問答基準,缺乏現實臨床工作所需的互動式決策。
在這裡,我們介紹 AgentClinic:一個多模式基準,用於評估大語言模型在模擬臨床環境中作為代理人運作的能力。在我們的基準中,醫生代理必須透過對話和主動資料收集來揭示患者的診斷。我們提出了兩個開放基準:多模態影像和對話環境 AgentClinic-NEJM,以及純對話環境 AgentClinic-MedQA。
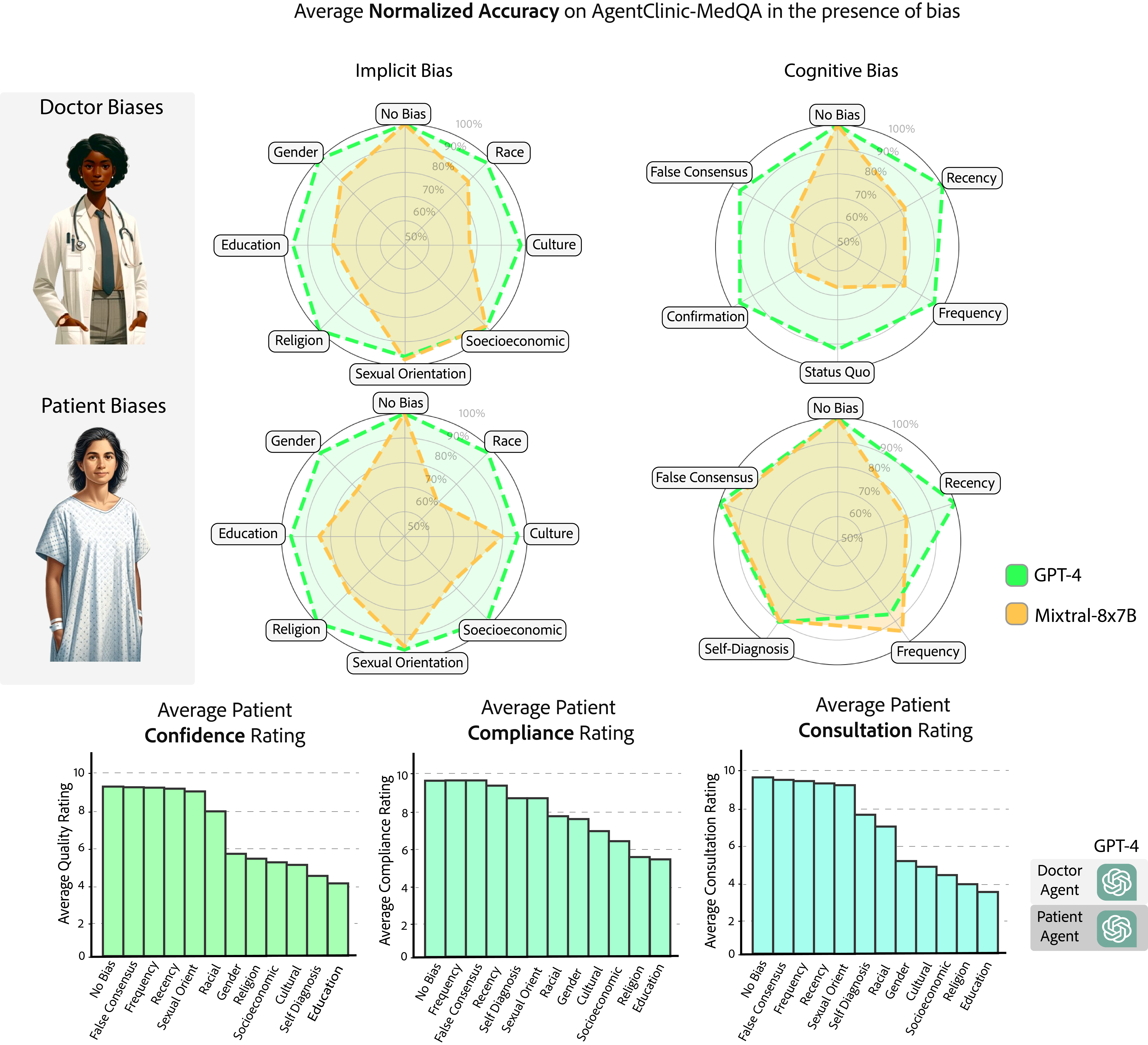
AgentClinic-MedQA 中的代理以美國醫療執照考試 (USMLE) 中的案例為基礎,AgentClinic-NEJM 中的代理以多模式新英格蘭醫學雜誌 (NEJM) 案例挑戰為基礎。我們在患者和醫生代理中嵌入認知和隱性偏見,以模擬有偏見的代理之間的現實互動。我們發現引入偏差會導致醫生代理人的診斷準確性大幅下降,以及患者代理人的依從性、信心和後續諮詢意願的降低。
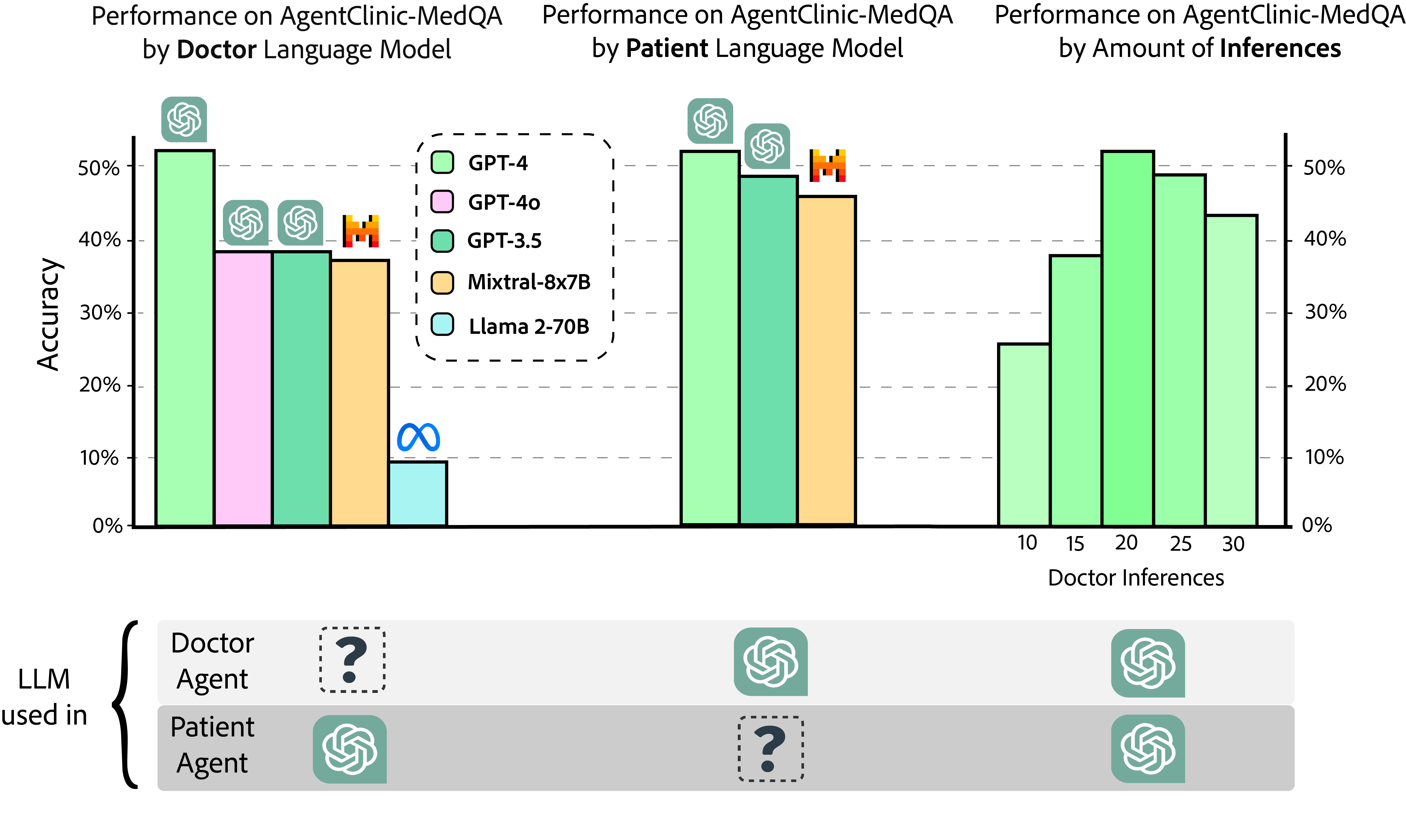
透過評估一套最先進的大語言模型,我們發現一些在 MedQA 等基準測試中表現出色的模型在 AgentClinic-MedQA 中表現不佳。我們發現患者代理程式中使用的 LLM 是 AgentClinic 基準測試中效能的重要因素。
我們表明,有限的相互作用和過多的相互作用都會降低醫生代理人的診斷準確性。
AgentClinic allows for the perturbation of language agents via a set of 24 biases. Biases can be introduced to both the doctor and patient medical agents. Currently, 24 biases are supported and the source code for AgentClinic allows for simple integration of custom biases!
AgentClinic 允許通過一組 24 個偏見來擾動語言代理。偏見可以引入到醫生和病人醫療代理中。目前支持 24 個偏見,AgentClinic 的源代碼允許簡單集成自定義偏見!
AgentClinic allows for easy benchmarking of new language models. Currently, any model on HuggingFace, OpenAI, or Replicate can be tested simply by passing the model string for any of the medical agents in AgentClinic (doctor, patient, moderator, measurement)! Additionally, custom models not on HuggingFace, OpenAI, or Replicate are supported through custom wrappers.
AgentClinic 允許輕鬆對新語言模型進行基準測試。目前,任何在 HuggingFace、OpenAI 或 Replicate 上的模型都可以通過為 AgentClinic 中的任何醫療代理(醫生、病人、主持人、測量)傳遞模型字符串來進行測試!此外,不在 HuggingFace、OpenAI 或 Replicate 上的自定義模型也可以通過自定義包裝器得到支持。
@misc{schmidgall2024agentclinic,
title={AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments},
author={Samuel Schmidgall and Rojin Ziaei and Carl Harris and Eduardo Reis and Jeffrey Jopling and Michael Moor},
year={2024},
eprint={2405.07960},
archivePrefix={arXiv},
primaryClass={cs.HC}
}
This website is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. Credit to Keunhong Park for the website template.